千问点奶茶时弹出的 UI 是怎么实现的,是生成式 UI 吗
前段时间千问奶茶免单很火,可以直接在 chat 界面输入“千问,帮我点杯奶茶”,后续就像我们自己操作一样,一步一步完成下单。
我们知道, AI chat 现在比较普遍的数据交互是 markdown,markdown 是渲染不出这种交互式UI 的,必须借助 HTML+CSS+JS 的能力才能做到。那么千问是怎么实现的呢?是交互过程中生成的 UI,前端做渲染吗?我感觉这个选项可以首先排除,具体原因下面会做分析。
一、方案概览
目前实现这种效果的常见方案主要有以下几种:
- 硬编码规则,根据服务端返回的特定格式的数据结构,映射到封装好的固定 UI。
- 让 AI 生成 html ,缺点是效果不稳定,需要持续调 prompt,这也是为什么我一开始觉得千问用的应该不是这个方案的原因。
- 定制一些卡片模板,告诉模型 input schema ,模型按数据结果填进来,缺点是模版还需要人力开发。
- google/a2ui 这类方案,让 AI Agent 直接驱动或生成用户界面,实现“对话即操作”“自然语言即界面”,与第二点的差异在于,前面 AI 输出的是代码,而这个方案生成的是schema,由引擎去解析,而不是直接渲染。
二、实现简介
首先应该有个输出定制的过程,输出格式可能是这样
// 硬编码规则 |
然后每一种方案的交互模式不一样的,可能是这样:
- 硬编码规则:自然语言 → 模型映射固定字段 → 按结构化内容渲染 UI
- AI 生成 HTML:自然语言 → 模型直接生成 HTML 字符串 → 渲染页面
- 模块化卡片模板:自然语言 → 映射为预定义模板 → 渲染模块卡片
- A2UI(组合式 Schema):自然语言 → Agent 生成 UI Schema → 引擎解析Schema,动态组件组合 → 渲染 UI
当然上面只是简单的流程,具体实现这里就不赘述了
三、方案对比
下面我通过一个实验 demo 来对比一下这几个方案,对比维度如下:
- 首次可用率(一次返回即可渲染)
- 回退率(需要重试/修复)
- 可控性(是否偏离预期结构)
- 开发成本(前端模板/解释器工作量)
- 迭代成本(改需求时改 prompt 还是改代码)
实验场长下面这样,我会在四种模式下各跑一次剧本生成流程,最终导出实验报告。
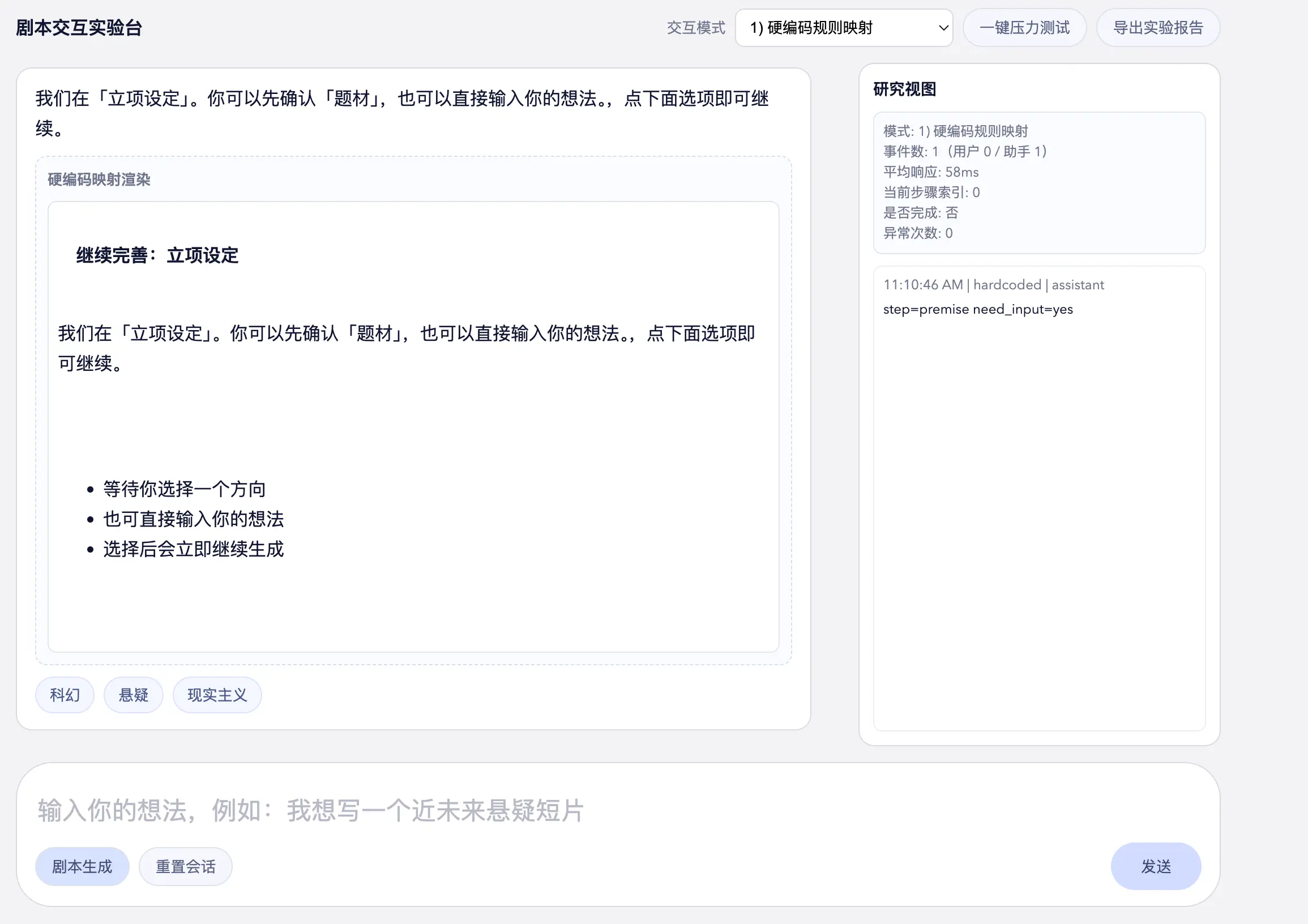
压测包含的场景
- 正常输入
- missing-fields(结构缺失)
- wrong-types(类型错误)
- html-unsafe(HTML 注入噪声)
- schema-noise(Schema 噪声)
下面是生成的报告
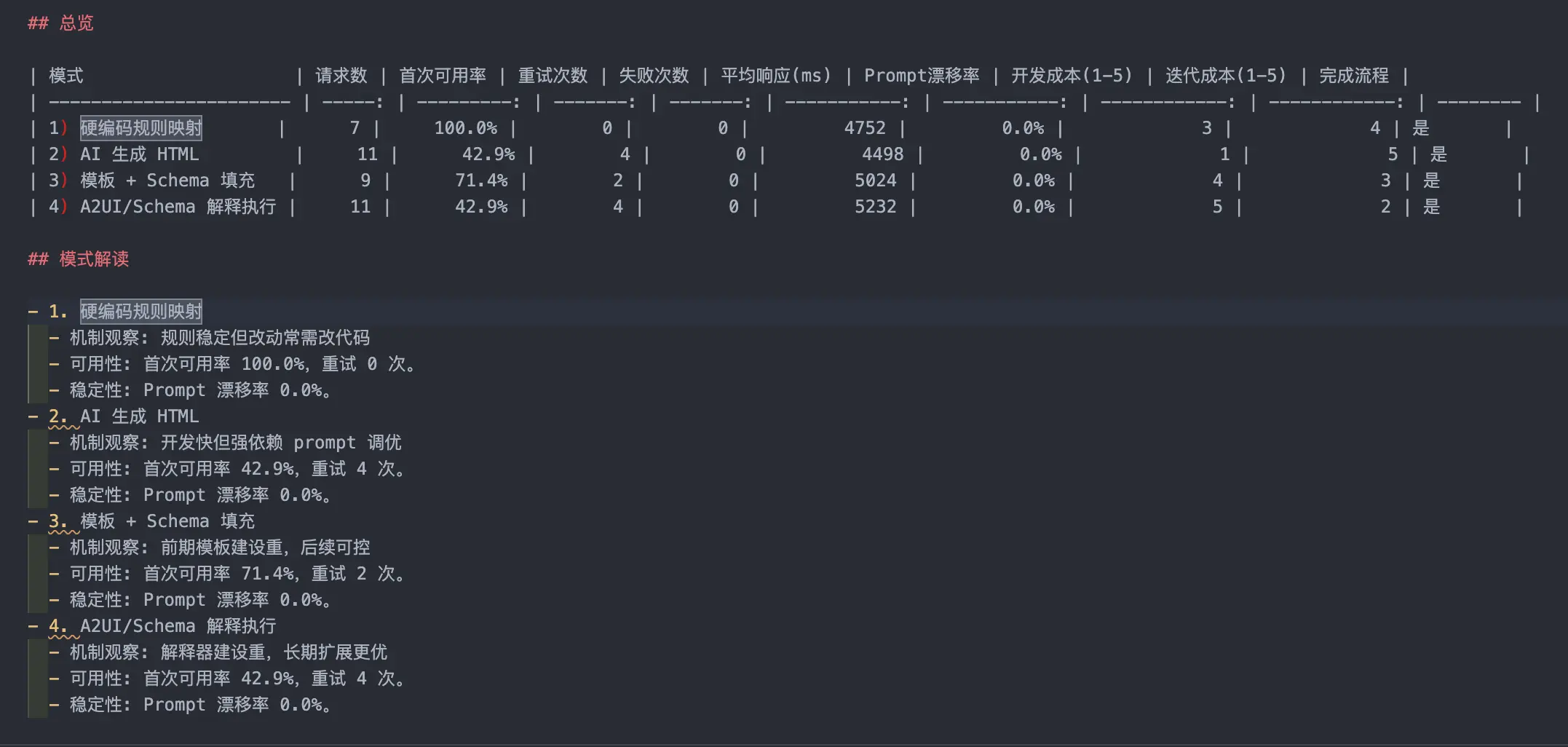

报告基本跟我的预期一致,不过数据准确性还得靠指标,我的指标计算也不一定对,仅供参考。
本文标题:千问点奶茶时弹出的 UI 是怎么实现的,是生成式 UI 吗
文章作者:Canace
发布时间:2026-02-28
最后更新:2026-02-28
原始链接:https://canace.site/qwen-milk-tea-ui/
版权声明:转载请注明出处
分享